 ボタンをクリックするか、Ctrl+O キーを押して、次に [検索] タブをクリックすると、次のタブが表示されます。
ボタンをクリックするか、Ctrl+O キーを押して、次に [検索] タブをクリックすると、次のタブが表示されます。
[ファイル] メニュー の [オプション] を選択するか、 ボタンをクリックするか、Ctrl+O キーを押して、次に [検索] タブをクリックすると、次のタブが表示されます。
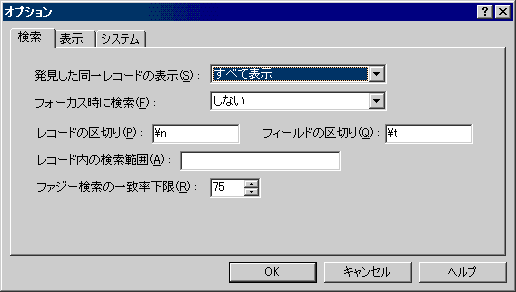
発見した同一レコードの表示
まったく同一のレコード (行) が複数発見された場合、それらを何度も表示するかどうかを指定します。
フォーカス時に検索
最前面のアプリケーションを LightGREP を切り替えたときに、自動的に検索を実行するかどうかを指定します。
ただし、クリップボードに単一行のテキストが格納されていない場合は、何も行われません。
レコードの区切り
検索されるファイルをレコード (行) に分割する境界を正規表現で指定します。既定では改行 (\n) です。つまり、通常の 1 行が 1 レコードになります。
LightGREP の検索はレコード単位で実行されます。複数のレコードにまたがる文字列は検索できません。したがって既定では改行を途中に含む文字列は検索できません。
レコードの区切りを変更すると、既存の索引ファイルはすべていったん削除され、次回の検索時に作り直されます。
この区切りは正規表現で指定するので、複数の文字や文字列を指定できます。たとえば「。」と「. 」の両方を区切りにするには、「[。.]」または「。|\.」と指定します。日本語と英語の文章で区切るには「[.?!][ \n]|[。?!]」とするのが一法です。
この正規表現に一致する実際の区切り文字列は、100 バイト以下でなければなりません。また、指定した区切りが 10,000 バイト以上にわたって現れない場合、レコードはそこで(正確には次の非全角第一バイト文字の直後で)切られます。
フィールドの区切り
レコードをフィールドに分割する境界を正規表現で指定します。既定ではタブ (\t) です。この指定は、[検索] ダイアログ ボックスの [フィールドに完全一致] オプションを指定したときにのみ意味を持ちます。
レコード内の検索範囲
レコードの特定の部分だけを検索する場合に指定します。
この検索範囲は、一組の ( ) を含む正規表現を使って指定します。各レコード上でこの正規表現が検索され、ヒットしたときに ( ) に一致した部分だけが検索対象となります。このボックスの正規表現がまったくヒットしないレコードは、検索対象になりません。
正規表現の要素をグループ化する目的で別の ( ) を使用する必要があるときは、代わりに (?: ) を使用してください。
たとえば、各レコードがタブ (\t) で区切られているとき、最初のタブの前の部分だけを検索するには、このボックスに「^([^\t]*)\t」と入力します。この正規表現は、「レコード先頭 (^) からタブ以外の文字 ([^\t]) が 0 個以上続き (*)、その後にタブ (\t) がある」と読むことができます。
いったんこのボックスを指定すると、以降の検索で常にこの制限が有効になりますので、設定したことを忘れないようにしてください。
ファジー検索の一致率下限
「ファジー検索」を参照してください。